Common Cost Functions
Object detection neural networks commonly use $\ell_1$-norm or $\ell_2$-norm for their cost function (aka. loss function). Our work shows that there is not a strong correlation between minimizing these commonly used losses and improving their IoU value.
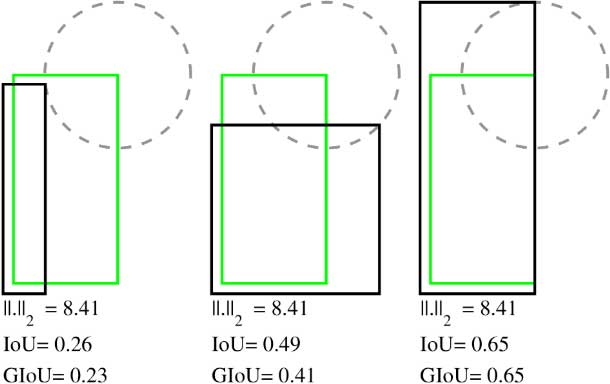
To understand why this is the case, recall that a rectangle can be represented parametrically in a variety of ways. For example, bounding boxes can be represented by their top-left corner $(x_1, y_1)$ and their bottom-right corner $(x_2, y_2)$, which can be written as $(x_1, y_1, x_2, y_2)$.
Alternatively, the $(x_c, y_c)$ coordinates for the center of the bounding box can be used in conjunction with the bounding box's width $w$ and height $h$ giving $(x_c, y_c, w, h)$.
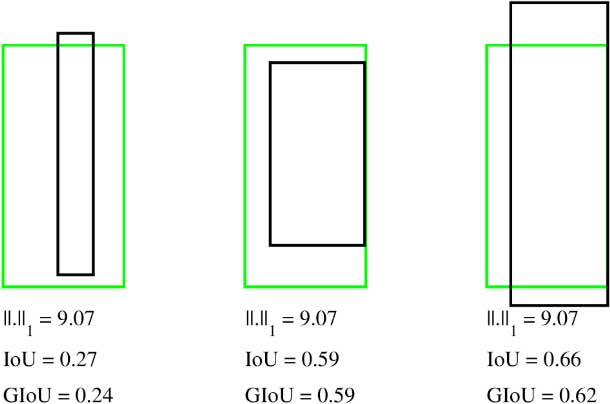
If we calculate $\ell_2$-norm distance, $||.||_2$ for the bounding boxes in both cases shown above and we calculate $\ell_1$-norm distance, $||.||_1$. Notice how the $\ell_n$-norm values are exactly the same, but their $IoU$ and $GIoU$ values are very different.
It is common practice to train a network by optimizing a loss function such as $\ell_1$-norm or $\ell_2$-norm, but then evaluate performance on a different function, such as $IoU$. Moreover, $\ell_n$-norm based losses are not scale invariant. Therefore, bounding boxes with the same level of overlap, but different scales will give different values. State of the art object detection networks deal with this problem by introducing ideas such as anchor boxes and non-linear representations, but even with these engineered tweaks, there is still a gap betwen the $\ell_n$-norm cost function and the $IoU$ metric.
$GIoU$ as a loss
Recall that in a neural network, any given loss function must be differentiable to allow for backpropagation. We see from the above example that in cases where there is no intersection, $IoU$ has no value and therefore no gradient. $GIoU$ however, is always differentiable.
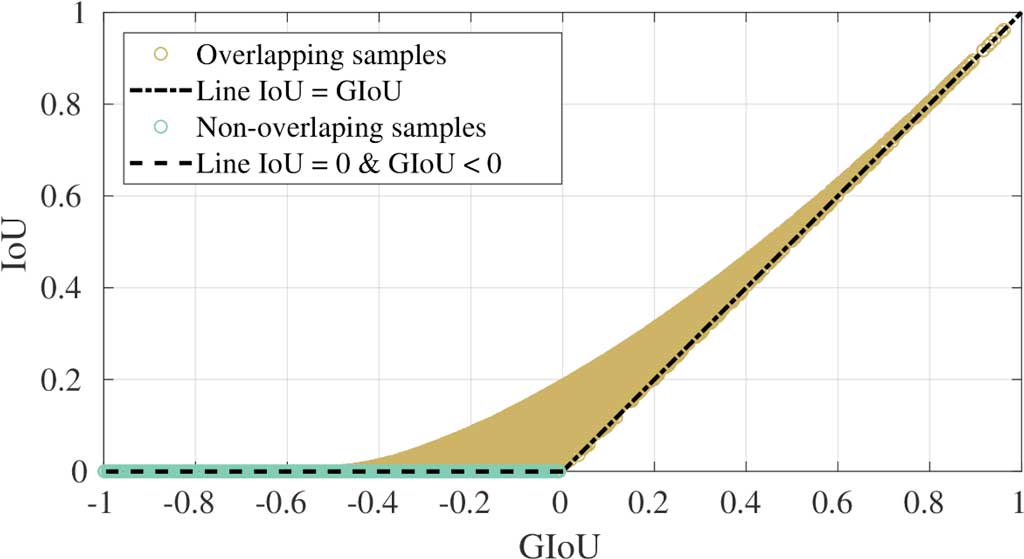
We sampled cases where the prediction bounding box overlaps (aka. intersects) the ground truth and cases where there is no intersection. The relationship between $IoU$ and $GIoU$ for these samples is shown in this figure.
From the plot, as from the formulation above, you can see that $GIoU$ ranges from -1 to 1. Negative values occur when the area enclosing both bounding boxes, e.g. $C$, is greater than $IoU$. As the $IoU$ component increases, the value of $GIoU$ converges to $IoU$.
Team









@article{Rezatofighi_2018_CVPR,
author = {Rezatofighi, Hamid and Tsoi, Nathan and Gwak, JunYoung and Sadeghian, Amir and Reid, Ian and Savarese, Silvio},
title = {Generalized Intersection over Union},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019},
}